요구사항
[f8477cfc] OrderController.request()
[f8477cfc] |-->OrderService.orderItem()
[f8477cfc] | |-->OrderRepository.save()
[f8477cfc] | |<--OrderRepository.save() time=1004ms
[f8477cfc] |<--OrderService.orderItem() time=1006ms
[f8477cfc] OrderController.request() time=1007ms서비스를 운영하면서 로그를 추적하기 위한 프로그램을 작성한다고 해보자.
HTTP 요청의 흐름대로 Controller, Service, Repository에서의 실행시간과 각각의 깊이를 나타내려면 어떻게 해야 할까?
가장 단순하게 생각해 보면 파라미터를 통해 넘겨주는 방법을 고려해 볼 수 있다.
이를 위해선 Controller에서 요청이 시작되면 해당 요청의 id 값과 깊이를 Service와 Repository에 넘겨주면 된다.
해결법
파라미터를 통해 HTTP 요청 id값 전달하기

위의 그림처럼 각각의 레이어에서 id와 level에 대한 데이터를 넘겨주는 방식이다.
id 값은 요청의 시작부터 끝까지 동일해야 하고 level은 레이어를 넘어갈 때마다 하나씩 커지거나 작아진다.
@GetMapping("/v2/request")
public String request(String itemId) {
TraceStatus status = null;
try {
status = trace.begin("OrderController.request()");
orderService.orderItem(status.getTraceId(), itemId); // 파라미터로 id값을 넘겨줘야 한다.
trace.end(status);컨트롤러에서 파라미터를 통해 서비스로 HTTP 요청 id값을 넘겨줘야 한다.
public void orderItem(TraceId traceId, String itemId) {
TraceStatus status = null;
try {
status = trace.beginSync(traceId,"OrderService.orderItem()");
orderRepository.save(status.getTraceId(), itemId);
trace.end(status);
...서비스레이어 또한 파라미터를 이용해 리포지토리레이어에 id값을 넘겨줄 수 있다.
이렇게 하면 컨트롤러, 서비스, 리포지토리 각각에서 하나의 요청에 대한 흐름별로 로그를 출력할 수 있다.
하지만 이런 식으로 파라미터를 넘기는 것은 유지보수에 좋지 않다. 만약 해당 클래스들이 인터페이스의 구현체라고 한다면
해당 인터페이스 구현체들의 모든 파라미터를 변경해야 하는 번거로움이 발생한다.
객체의 필드 값 사용하기
객체를 선언하고 그 객체의 필드값을 활용하는 방식이다.
@Slf4j
public class FieldLogTrace implements LogTrace{
private static final String START_PREFIX = "-->";
private static final String COMPLETE_PREFIX = "<--";
private static final String EX_PREFIX = "<X-";
private TraceId traceIdHolder; // traceIdHolder 동기화, 동시성 이슈 발생
...로그를 출력하는 클래스를 만들 때 TraceId 객체(id와 level을 가지는 객체)를 담아두는 필드를 하나 선언한다.
@Configuration
public class LogTraceConfig {
@Bean
public LogTrace logTrace() {
return new FieldLogTrace();
}
}이후 해당 클래스를 빈으로 등록해 준다. 스프링의 기본설정은 빈을 등록할 때 싱글톤 빈으로 등록한다.
따라서 현재 애플리케이션에서 FieldLogTrace객체는 단 하나만 존재하게 된다.

만약 요청을 한 번만 한다면 의도한 대로 정상적으로 동작한다.

하지만 실행로직에 Thread.sleep() 을 걸고 이전 HTTP 요청이 완료되기 전에 새로운 HTTP 요청을 연속적으로
보내보면 위와 같이 비정상적인 실행 흐름을 보이는 것을 볼 수 있다. 남겨진 로그를 살펴보면 첫 번째 요청은 2번 스레드가, 두 번째 요청은
3번 스레드가 실행 중인 것을 확인할 수 있는데 2개의 스레드에서 하나의 FieldLogTrace객체의 필드값을 조회하고 수정하면서
동시성 문제가 발생했다. 이를 해결하기 위한 방법 중 하나는 ThreadLocal을 사용하는 것이다.
ThreadLocal 사용하기
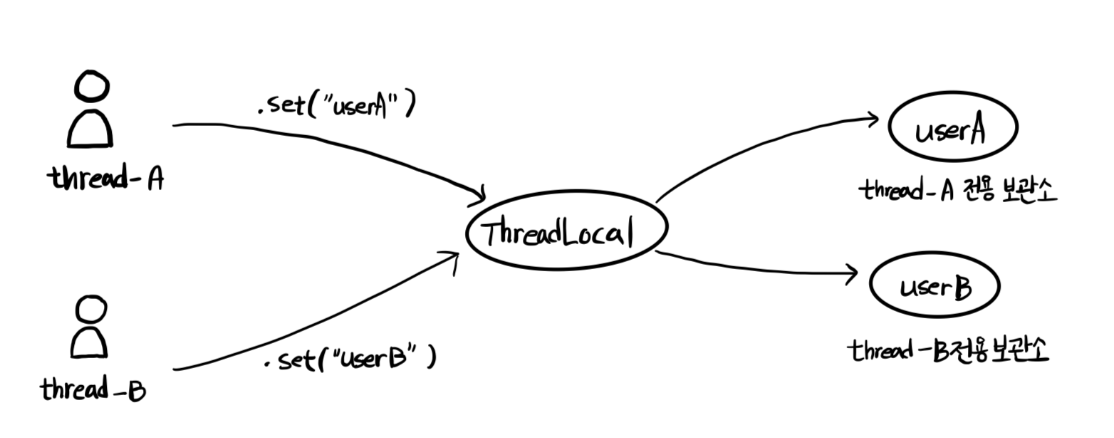
스레드 로컬이란 쉽게 말하면 각각의 스레드마다 별도의 보관소를 생성해 준다고 생각하면 된다.
스레드A가 ThreadLocal을 통해 데이터를 저장하면 스레드A를 위한 별도의 보관소에 저장하고
이후 조회를 요청하면 스레드A의 보관소에서 데이터를 읽어온다.
저장 할때는 .set() 메서드를 사용하고 조회할 때는 .get() 메서드를 사용해서 조회한다.
@Slf4j
public class ThreadLocalLogTrace implements LogTrace {
private static final String START_PREFIX = "-->";
private static final String COMPLETE_PREFIX = "<--";
private static final String EX_PREFIX = "<X-";
// private TraceId traceIdHolder; // traceIdHolder 동기화, 동시성 이슈 발생
private ThreadLocal<TraceId> traceIdHolder = new ThreadLocal<>();
...ThreadLocal<T> 로 T타입에 대한 ThreadLocal을 생성할 수 있다.
그 외에는 이전에 필드를 이용한 코드와 동일하다.
@Configuration
public class LogTraceConfig {
@Bean
public LogTrace logTrace() {
return new ThreadLocalLogTrace();
// return new FieldLogTrace();
}
}필드를 이용했던 설정에서 ThreadLocal을 이용하는 설정으로 변경해 준다.
ThreadLocal 주의사항
ThreadLocal을 사용할 때는 주의해야 하는 점이 있는데 그건 사용이 끝난 ThreadLocal은 반드시
.remove() 메서드를 통해서 삭제해줘야 한다는 것이다. 만약 삭제하지 않으면 어떤 상황이 발생할 수 있는지
한번 알아보자.

먼저 사용자A가 HTTP 요청을 통해 데이터를 저장하려고 한다.
이때 스레드풀에서 스레드1이 할당되었다. 이제 스레드 로컬을 통해 사용자A의 데이터를 저장한다.
이때 스레드1 전용 보관소에 사용자A의 데이터가 저장된다.
작업이 끝나면 스레드풀에 스레드1을 반환한다. (스레드를 생성하는 비용이 비싸므로 사용이 끝난
스레드를 제거하지 않고 보통 스레드 풀을 통해서 스레드를 재사용한다)

이후 사용자B가 조회를 요청한다. 이때 우연히 스레드풀에서 스레드1이 할당된다.
스레드 로컬을 통해 데이터를 조회하려고 하면 이전에 삭제하지 않아 남아있던 사용자A데이터가
반환된다. 결국 사용자B는 사용자A의 데이터를 조회할 수 있게 된다.
위와 같은 상황을 방지하기 위해선 꼭 사용이 끝난 ThreadLocal은 .remove() 를 이용해
제거해줘야 한다.
private void releaseTraceId() {
TraceId traceId = traceIdHolder.get();
if (traceId.isFirstLevel()) {
traceIdHolder.remove(); // 사용이 끝나면 꼭 제거해줘야 한다.
} else {
traceIdHolder.set(traceId.createPreviousId());
}
}사용이 끝난 ThreadLocal을 제거해 준다.
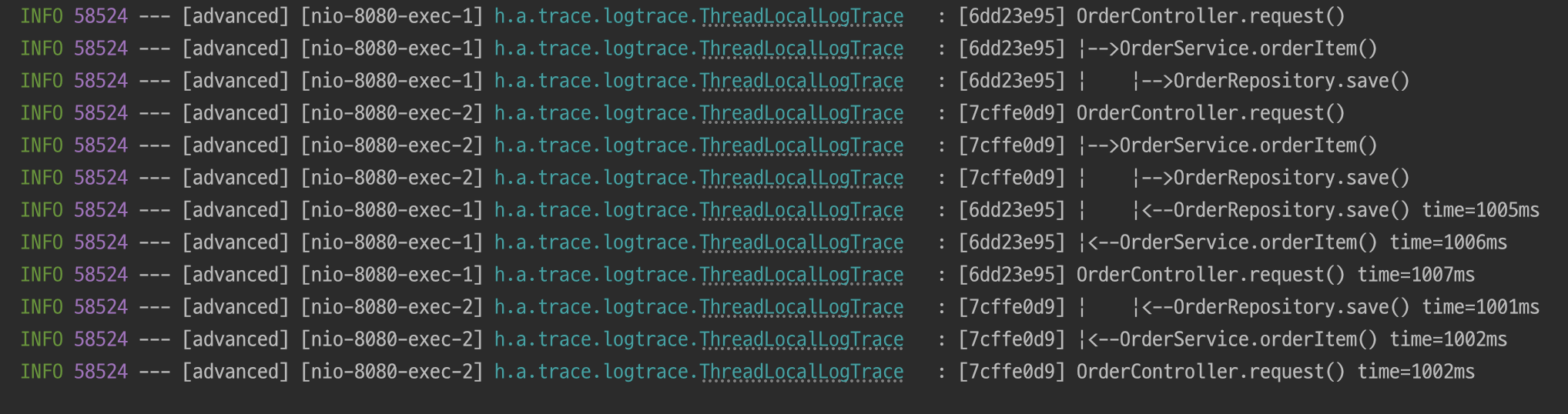
이제 다시 연속적으로 실행하여 동시성 문제를 유도해도 각각의 스레드가 스레드 로컬을 사용하여
동시성 문제가 발생하지 않는 걸 확인할 수 있다.
참고
'Back-end > Java' 카테고리의 다른 글
| [Java] 객체지향 - 다형성(역할과 구현) (2) | 2024.08.10 |
|---|